Course "Architecture of Multi-Processor Systems"
TP9: Cooperative Multi-Tasking Applications
(franck.wajsburt@…)
A. Objectives
In this tutorial, we are interested in synchronization mechanisms in parallel cooperative software applications. In the parallel applications of TP5 or TP8, the different tasks did not explicitly communicate with each other. In this TP9, the different tasks of the parallel application exchange information through shared memory areas, following a producer/consumer scheme, and must therefore synchronise much more strongly.
The main goal of this tutorial is therefore to analyse different synchronization mechanisms between tasks sharing the same address space.
B. Hardware architecture
The same generic multi-processor hardware architecture is used as in the previous labs. We will successively use an architecture with 2 processors, then an architecture with 6 processors.

The archive multi_tp9.tgz contains the files you will need. Create a working directory tp9, copy the files tp5_top.cpp and tp5.desc, and unpack the archive into this directory.
C. Producer / Consumer Application
The software application defined in the main_bipro.c file in the soft directory has two software tasks that run in parallel on the two processors proc[0] and proc[1], and communicate with each other through a shared global variable called BUFFER. The producing task executes a loop on processor proc[0] in which it writes an integer value to the BUFFER variable, after displaying this value on its private terminal TTY[0]. The consuming task executes a loop on processor proc[1] in which it reads the value contained in the BUFFER buffer and displays it on its private terminal TTY[1]. For each of the two tasks, the period between two writes (or between two reads) can be adjusted with a timing loop.
Question C1: By analysing the C code of the two functions producer() and consumer() in the file main_bipro.c, describe what you think you see on the two terminals TTY[0] and TTY[1].
As in the previous tutorials, it is the boot code that launches the two tasks consumer and producer on two different processors,
Question C2: Complete the assembly code contained in the file reset.s so that the tasks producer and consumer are launched on the processors 0 and 1 respectively.
Compile the software application in the soft directory, using the Makefile provided, and run this application for different values of the timing variables defined at the beginning of the main_bipro.c file:
- PRODUCER_DELAY = 10 / CONSUMER_DELAY = 1000
- PRODUCER_DELAY = 1000 / CONSUMER_DELAY = 10
Run the application on the virtual prototype with two processors, ensuring that the SNOOP mechanism is enabled:
./simul.x -NPROCS 2 -SNOOP 1
Question C3: What behaviour do you observe? How do you interpret these results?
D. Synchronisation by SET/RESET toggle
In order for the communication between tasks to be independent of the execution time of the tasks, the tasks must be synchronised with each other. There are two constraints to respect:
- The consuming task must not read the data (n) until it has been written to the buffer by the producing task.
- The producing task must not write data (n + 1) to the buffer until data (n) has been read by the consuming task.
A first synchronisation technique consists in using a SET/RESET flip-flop: another global variable SYNC is introduced, which has the value 0 when the BUFFER communication buffer is empty, and has the value 1 when it is full. Like the BUFFER variable, the SYNC variable is a global variable, stored in the seg_data segment.
- The producing task only writes a value to the BUFFER buffer when SYNC is 0. To do this, it tests the value of SYNC in an active wait loop. When it has checked that SYNC is 0, the producing task writes a data to the BUFFER buffer, before setting SYNC to 1.
- The consuming task only reads a value from the BUFFER buffer when SYNC is set to 1. To do this, it tests the value of SYNC in an active wait loop. When it has checked that the SYNC variable has the value 1, the consuming task reads the data contained in BUFFER, before setting SYNC to 0.
Question D1: The value of the SYNC variable can be changed by the two tasks producer and consumer running in parallel. Explain why there is no risk of inconsistency due to concurrent accesses to this variable.
Modify the software application defined in the file main_bipro.c, to define the global variable SYNC, and introduce the active wait loops on SYNC in the two functions producer() and consumer().
Question D2: Recompile the software application. and run this synchronised software application using different values of the CONSUMER_DELAY and PRODUCER_DELAY parameters, to check the effectiveness of the synchronisation mechanism. Compare the runtimes with and without synchronisation. To calculate the execution time, we will take the termination date of the task that terminates last.
Like most segments stored in memory, the seg_data segment containing the global variables is cacheable. The SYNC and BUFFER variables can therefore be copied into the two caches associated with the proc[0] and proc[1] processors.
Question D3: Why does this cachability introduce a risk of malfunction?
The software solution to this cache coherence problem is to group shared variables into a non-cacheable segment. It requires the programmer to make the effort to identify all shared variables, and to have the software tools to control the memory placement of these variables. This solution can be used in embedded applications, where the entire software generation chain is controlled.
If one wants to re-use existing software, this approach is not applicable, and cache consistency must be guaranteed by the hardware. This explains why all current multi-core PCs use a SNOOP mechanism.
Restart the simulation by disabling the snoop mechanism, using the argument (-SNOOP 0) on the command line.
Question D4: Interpret the observed behaviour.
Question D5: What do you think is the main hardware cost caused by the SNOOP mechanism? Hint: the SNOOP_FSM automaton has only 3 states, and can be implemented in about 10 logic gates. The cost of the automaton itself can therefore be considered negligible.
E. Synchronisation problems related to instruction reordering
The SET/RESET synchronisation mechanism used above is based on the assumption that read or write memory accesses are indeed performed in the order they are written in the program. The producer program, for example, writes a new value to variable BUFFER, before writing the value 1 to variable SYNC.
But, to minimise execution time, the compiler (or the hardware itself) can change the order of writes and/or reads to memory, when they concern different addresses, because the compiler and the hardware are unaware that there is a relationship between the two variables BUFFER and SYNC. If the SYNC variable changes to 1 in memory before the new value of the BUFFER variable is written to memory, it is possible that the consumer reads a false value.
It is therefore absolutely necessary to introduce directives into the C code, allowing the control of optimisations carried out by the compiler or by the hardware. In C, we use the macro __sync_synchronize() which has the following effect:
- all reads or writes before the macro will be executed by the processor before the macro is passed.
- All reads or writes after the macro will be executed by the processor after the macro is passed.
Question E1: Modify the code of the functions producer() and consumer() to introduce the macros strictly guaranteeing the access order to the shared variables SYNC and BUFFER.
Question E2: Recompile and re-execute the software application. How has the binary code been modified by the introduction of the macro? You have to look in the file app.bin.txt. How is the execution time modified?
General Note: You have to be very careful with synchronizations: There is nothing worse than a parallel program that falls into operation... by chance, with a particular compiler, for a particular machine, but that will behave differently with another compiler or on another machine...
F. Software FIFO Synchronisation
The main limitation of the SET/RESET toggle synchronisation mechanism is that this communication channel supports only one producer and one consumer. A second limitation is that the communication channel can only contain one piece of data. This data can be of any type: a byte, a 32-bit integer, or a more complex object, but the buffer can only contain one value, since it has only two states: the buffer is either full or empty but there is no intermediate state.
In this section, we introduce another mechanism of communication between tasks, supporting several producers and several consumers, and where the communication buffer can contain N data of the same type instead of only one. The FIFO is a queue, which allows a temporal decoupling between the producer and the consumer task: The producer can produce several data before being blocked because the buffer is full. Symmetrically, the consumer can consume several data before being blocked because the buffer is empty.
As the name suggests, a FIFO (First In / First Out) channel is a communication channel where data is read by the consumer(s) in the same order as it was written by the producer(s). A FIFO with a storage capacity of N data can therefore be in (N + 1) states, since it can contain 0, 1, ... N data.
In a software FIFO of capacity N, the data is stored in a circular array BUF[N] in memory, and the state of the FIFO is defined by three variables, which are also stored in memory:
- PTW (write pointer): number of the first free cell to be written (modulo N)
- PTR (read pointer): number of the first full cell to be read (modulo N)
- STS (FIFO content): total number of data present in the FIFO (N + 1 possible values)
The general principle is as follows:
- The producing task that wishes to write data consults the STS variable in an active waiting loop until STS is strictly less than N. When this is the case, it writes the data in the BUFFER[PTW] box, then increments PTW (modulo N), and increments STS.
- The consuming task that wishes to read data consults the STS variable in an active wait loop, until STS is strictly greater than 0. When this is the case, it reads the data in the BUFFER[PTR] box, then increments PTR (modulo N), and decrements STS.
- Since the FIFO is managed as a circular buffer, both PTR and PTW pointers must be incremented modulo N.
Note on concurrent access to shared variables:
- The state variable STS and the two pointers PTW and PTR ensure that the same BUFFER[i] cell is never simultaneously accessed for reading and writing. There is therefore no risk of concurrent accesses for the BUFFER[i] variables
- In the case where there is only one producing and one consuming task, the variable PTW is only modified by the one producing task, and the variable PTR is only modified by the one consuming task. PTR and PTW are therefore not shared variables. The only shared variable that can be modified simultaneously by both tasks is the variable STS.
- In the case where there are several producing tasks and several consuming tasks, the three variables PTW, PTR, STS can be accessed concurrently by several tasks to be incremented or decremented.
Concurrent accesses to the variables STS, PTW and PTR can lead to inconsistencies: for example, if a producer and a consumer simultaneously read the variable STS to modify it, the final value will be wrong: depending on the order in which the entries are made, one will obtain (N + 1) or (N - 1), whereas the value N should be unchanged.
To solve this concurrent access problem, one technique is to guarantee exclusive access to the communication channel by a binary lock.
Finally, any task (producer or consumer) that wishes to access the FIFO must follow the following protocol:
- take the lock (this may result in an active wait).
- test the state of the STS variable to determine if the transfer is possible (FIFO not full for a write / FIFO not empty for a read)
- if the transfer is impossible, release the lock and return to 1.
- if the transfer is possible, perform the transfer, increment the concerned pointer, modify STS, then release the lock.
The file main_fifo.c contains a producer / consumer application using a FIFO communication channel. In the previous application, the access periods (read and write) were constant and defined by the vaiables PRODUCER_DELAY and CONSUMER_DELAY. In this application, the rand() function is used to more realistically model a variable (and unpredictable) time between two accesses to the communication channel.
The _ioc_lock lock used in TP8 was a system space lock, used by the operating system to sequence accesses to the disk controller. The lock used here to protect exclusive access to the communication channel is an "in user space" lock, which is handled directly by the application code through the two functions lock_acquire() for lock acquisition, and lock_release() for lock release. They are defined in the main_fifo.c file. To ensure fair allocation between tasks, this lock implements a ticket technique, which requires defining a structure containing two integer variables: the variable free represents the number of the next free ticket. The variable current contains the ticket number of the current owner.
Question F1: The communication channel is defined as a C structure of the application program. Why is this structure declared as a global variable? What are the different fields of the structure?
Question F2: Why is it better to use a ticket lock rather than a simple lock as in TP8?
Question F3: What are the arguments to the two functions lock_acquire() and lock_release()?
Question F4: Describe exactly what the lock_acquire() function does to take the lock. Why is the function atomic_increment(), called by the function lock_acquire(), written in assembly? Explain very precisely what this atomic_increment() function does.
Question F5: What does the lock_release() function do to release the lock? Explain why this function does not need to be written in assembly?
Question F6: Why does a task that cannot perform its transfer because of the FIFO state (FIFO full for a producer / FIFO empty for a consumer) have to release the lock before trying again? What happens if it does not release the lock?
Question F7: Complete the code for the functions fifo_read() and fifo_write() which must achieve the communication protocol described above.
Compile the software application main_fifo.c by modifying the Makefile in the soft directory and run it for different values of the DEPTH parameter defining the number of FIFO boxes, without forgetting to activate the SNOOP:
$ ./simul.x -NPROCS 2 -SNOOP 1
Question F8: Find the termination dates of the two tasks, and enter these values in the table below. What conclusions can be drawn from this?
| DEPTH | 1 | 2 | 4 | 8 |
| Producer | ||||
| Consumer |
In parallel applications, it is interesting to evaluate the computation time and the communication time separately.
- The computation time is an intrinsic characteristic of each task, and corresponds to the number of cycles used by the task to perform the computations for which it is responsible.
- The communication time is the time used to perform the read or write operations in the communication channels (including the time spent in the waiting loops related to synchronisation).
Question F9: Evaluate the average cost (in number of cycles) of a communication operation between two tasks. To do this, reduce to a strict minimum the calculation times other than the calls to the fifo_read() and fifo_write() functions in the producer() and consumer() tasks:
- remove timeouts,
- remove the display inside the loop
- increase the number of iterations (1000 iterations)
The increase in the number of iterations makes it possible to neglect the cost of the boot phase, and the cost of the two displays at the beginning and end of the two functions producer() and consumer().
G. Multi-tasking software application
The lock-protected FIFO communication channel supports multiple producers and multiple consumers.
Modify the main_fifo.c file to write a third software application in a main_router.c file, with 6 tasks and two communication channels A and B, according to the following scheme: one producer task, four processing tasks, and one consumer task.
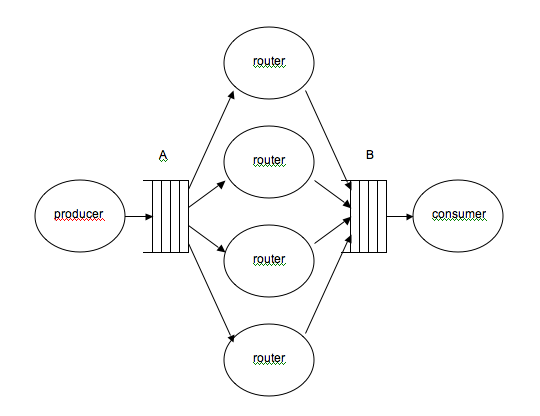
This structure corresponds, for example, to a network routing application, where the producer task writes descriptors of WIFI network packets received at an RF receiver into channel A. The processing tasks are responsible for analysing the header of each received packet to determine to which destination the packet should be routed, and enriching the contents of the packet to mark that destination, before copying the packet descriptor to the B channel. Finally, the consuming task reads back the packet descriptors and sends them to the output channel corresponding to the chosen destination...
Our goal here is simply to verify that the communication channels are working properly. The tasks therefore simply exchange numbered tokens rather than packet descriptors, thus verifying that no tokens are lost and that no tokens are transmitted twice.
- The producer task sends tokens numbered from 1 to 50 in channel A, displaying a message on its terminal for each token transmitted, and stops after sending 50 tokens.
- The router task is replicated 4 times. It executes an infinite loop in which it consumes a token in channel A, displays the token number on its terminal, and transmits it to channel B after a random time defined by the rand() function.
- The consumer task has a local array[50], and executes a loop of 50 iterations in which it reads a token from channel B, and stores the read token in the cell of the array corresponding to the token number, checking that the token has not already been received. After 50 iterations, it exits the loop, and checks that all tokens have been received (i.e. array[i] == i for all i) and stops with a diagnostic message.
Question G1: What needs to be changed in the reset.s file to run six tasks on six different processors?
Question G2: The purpose of the lock is to prohibit concurrent access to the same resource (hardware or software). Why is it better to define an independent lock for each communication channel, rather than defining a single lock for all channels?
H. Report
The answers to the above questions should be written in a text editor and this report must be handed in at the beginning of the next practical session. In the same way, the simulator will be checked (by pairs) at the beginning of the next week's practical session.