Cours "Architecture des Systèmes Multi-Processeurs"
TP9 : Applications multi-tâches coopératives
(franck.wajsburt@…)
A. Objectifs
On s'intéresse dans ce TP aux mécanismes de synchronisation dans les applications logicielles parallèles coopératives. Dans les applications parallèles du TP5 ou du TP8, les différentes tâches ne communiquaient pas explicitement entre elles. Dans ce TP9, les différentes tâches de l'application parallèle échangent des information à travers des zones mémoire partagées, suivant un schéma producteur/consommateur, et doivent donc se synchroniser de façon beaucoup plus forte.
Le but principal de ce TP est donc d'analyser différents mécanismes de synchronisation entre tâches partageant le même espace d'adressage.
B. Architecture matérielle
On utilise la même architecture matérielle multi-processeurs générique que pour les TPs précédents. On utilisera successivement une architecture comportant 2 processeurs, puis une architecture comportant 6 processeurs.

L'archive attachment:multi_tp9.tgz contient les fichiers dont vous aurez besoin. Créez un répertoire de travail tp9, copiez les fichier tp5_top.cpp et tp5.desc, et décompressez l'archive dans ce répertoire.
C. Application producteur / consommateur
L'application logicielle définie dans le fichier main_bipro.c du répertoire soft comporte deux tâches logicielles qui s'exécutent en parallèle sur les deux processeurs proc[0] et proc[1], et communiquent entre elles à travers une variable globale partagée appelée BUFFER. La tâche productrice exécute sur le processeur proc[0] une boucle dans laquelle elle écrit une valeur entière dans la variable BUFFER, après avoir affiché cette valeur sur son terminal privé TTY[0]. La tâche consommatrice exécute sur le processeur proc[1] une boucle dans laquelle elle lit la valeur contenue dans le tampon BUFFER et l'affiche sur son terminal privé TTY[1]. Pour chacune des deux tâches, on peut ajuster la période entre deux écritures (ou entre deux lectures) avec une boucle de temporisation.
Question C1 : En analysant le code C des deux fonctions producer() et consumer() dans le fichier main_bipro.c, décrivez ce que vous pensez voir sur les deux terminaux TTY[0] et TTY[1].
Comme dans les TPs précédents, c'est le code de boot qui lance les deux tâches consumer et producer sur deux processeurs différents.
Question C2 : Complétez le code assembleur contenu dans le fichier reset.s pour que les tâches producer et consumer soient lancées sur les processeurs 0 et 1 respectivement.
Compilez l'application logicielle dans le répertoire soft, en utilisant le Makefile fourni, et exécutez cette application pour différentes valeurs des variables de temporisation définies au début du fichier main_bipro.c:
- PRODUCER_DELAY = 10, CONSUMER_DELAY = 1000
- PRODUCER_DELAY = 1000, CONSUMER_DELAY = 10
Exécutez l'application sur le prototype virtuel à deux processeurs, en vous assurant que le mécanisme de SNOOP est activé:
./simul.x -NPROCS 2 -SNOOP 1
Question C3 : Quel comportement observez vous ? Comment interprétez-vous ces résultats ?
D. Synchronisation par bascule SET/RESET
Pour que la communication entre les tâches soit indépendante de la durée d'exécution des tâches, il faut synchroniser les tâches entre elles. Il y a deux contraintes à respecter :
- La tâche consommatrice ne doit pas lire la donnée (n) tant que celle-ci n'a pas été écrite dans le tampon par la tâche productrice.
- La tâche productrice ne doit pas écrire la donnée (n+1) dans le tampon tant que la donnée (n) n'a pas été lue par la tâche consommatrice.
Une première technique de synchronisation consiste à utiliser une bascule SET/RESET : on introduit une autre variable globale SYNC, qui possède la valeur 0 lorsque le tampon de communication BUFFER est vide, et possède la valeur 1 lorqu'il est plein. Comme la variable BUFFER, la variable SYNC est une variable globale, stockée dans le segment seg_data.
- La tâche productrice n'écrit une valeur dans le tampon BUFFER que quand la variable SYNC a la valeur 0. Pour cela, elle teste la valeur de SYNC dans une boucle d'attente active. Quand elle a vérifié que SYNC vaut 0, la tâche productrice écrit une donnée dans le tampon BUFFER, avant de mettre SYNC à 1.
- La tâche consommatrice ne lit une valeur dans le tampon BUFFER que quand la variable SYNC a la valeur 1. Pour cela, elle teste la valeur de SYNC dans une boucle d'attente active. Quand elle a vérifié que la variable SYNC a la valeur 1, la tâche consommatrice lit la donnée contenue dans BUFFER, avant de mettre SYNC à 0.
Question D1 : La valeur de la variable SYNC peut être modifiée par les deux tâches producer et consumer qui s'exécutent en parallèle. Expliquez pourquoi il n'y a pas de risque d'incohérence liée aux accès concurents à cette variable.
Modifiez l'application logicielle définie dans le fichier main_bipro.c, pour définir la variable globale SYNC, et introduire les boucles d'attente active sur SYNC dans les deux fonctions producer() et consumer().
Question D2 : Recompilez l'application logicielle. et exécutez cette application logicielle synchronisée en utilisant différentes valeurs des paramètres CONSUMER_DELAY et PRODUCER_DELAY, pour vérifier l'efficacité du mécanisme de synchronisation. Comparez les durées d'exécution avec et sans synchronisation. Pour calculer la durée d'exécution, on prendra la date de terminaison de la tâche qui se termine en dernier.
Comme la plupart des segments stockés en mémoire, le segment seg_data contenant les variables globales est cachable. Les variables SYNC et BUFFER, vont donc pouvoir être recopiées dans les deux caches associés aux processeur proc[0] et proc[1].
Question D3 : Pourquoi cette cachabilité introduit-elle un risque de dysfonctionnement ?
La solution logicielle à ce problème de cohérence des caches consiste à regrouper les variables partagées dans un segment non-cachable. Elle impose que le programmeur fasse l'effort d'identifier toutes les variables partagées, et dispose des outils logiciels permettant de contrôler le placement en mémoire de ces variables. Cette solution peut être employée dans les applications embarquées, où on contrôle entièrement la chaîne de génération du logiciel.
Si on veut réutiliser du logiciel existant, cette approche n'est pas applicable, et il faut que la cohérence des caches soit garantie par le matériel. Ceci explique que tous les PCs multi-cores actuels utilisent un mécanisme de cohérence tel que le SNOOP.
Relancez la simulation en désactivant le mécanisme de snoop, grâce à l'argument (-SNOOP 0) sur la ligne de commande.
Question D4 : Interprétez le comportement observé.
Question D5 : Quel est, selon vous, le principal coût matériel causé par le mécanisme de SNOOP ? Indication : l'automate SNOOP_FSM ne comporte que 3 états, et peut être implanté en une dizaine de portes logiques. Le coût de l'automate lui-même peut donc être considéré comme négligeable.
E. Problèmes de synchronisation liés au réordonnancement des instructions
Le mécanisme de synchronisation SET/RESET utilisé ci-dessus repose sur l'hypothèse que les accès à la mémoire en lecture ou en écriture sont bien effectués dans l'ordre où ils sont écrits dans le programme. Le programme producteur, par exemple, écrit une nouvelle valeur dans la variable BUFFER, avant d'écrire la valeur 1 dans la variable SYNC.
Mais, pour minimiser les temps d'exécution, le compilateur (ou le matériel lui-même) peut modifier l'ordre des écritures et/ou des lectures en mémoire, quand elles concernent des adresses différentes, car le compilateur et le matériel ignorent qu'il existe une relation entre les deux variables BUFFER et SYNC. Si la variable SYNC passe à 1 en mémoire avant que la nouvelle valeur de la variable BUFFER soit écrite en mémoire, il est possible que le consommateur lise une valeur fausse.
Il faut donc absolument introduire dans le code C des directives, permettant de contrôler les optimisations réalisées par le compilateur ou par le matériel. En C, on utilise la macro __sync_synchronize() qui a l'effet suivant:
- toutes les lectures ou écritures situées avant la macro seront obligatoirement exécutées par le processeur avant que la macro soit franchie.
- toutes les lectures ou écritures situées après la macro seront obligatoirement exécutées par le processeur après franchissement de la macro.
Question E1 : Modifiez le code des fonctions producer() et consumer() pour introduire les macros garantissant strictement l'ordre d'accès aux variables partagées SYNC et BUFFER.
Question E2 : Recompilez et re-exécutez l'application logicielle. Comment le code binaire a-t-il été modifié par l'introduction de la macro ? Il faut aller regarder dans le fichier app.bin.txt. Comment le temps d'exécution est-il modifié ?
Remarque Générale: Il faut être très prudent avec les synchronisations: Il n'y a rien de pire qu'un programme parallèle qui tombe en marche... par chance, avec un compilateur particulier, pour une machine particulière, mais qui aura un comportement différent avec un autre compilateur ou sur une autre machine...
F. Synchronisation par FIFO logicielle
La principale limitation du mécanisme de synchronisation par bascule SET/RESET, est que ce canal de communication ne supporte qu'un seul producteur et un seul consommateur. Une seconde limitation est que le canal de communication ne peut contenir qu'une seule donnée. Cette donnée peut être de n'importe quel type : un octet, un entier 32 bits, ou un objet plus complexe, mais le tampon ne peut contenir qu'une seule valeur, puisqu'il ne possède que deux états: le tampon est soit plein, soit vide mais il n'y a pas d'état intermédiaire.
On introduit dans cette partie un autre mécanisme de communication entre tâches, supportant plusieurs producteurs et plusieurs consommateurs, et où le tampon de communication peut contenir N données du même type putôt qu'une seule. La FIFO est une file d'attente, qui permet un découplage temporel entre la tâche productrice et la tâche consommatrice : le producteur peut produire plusieurs données avant d'être bloqué parce que le tampon est plein. Symétriquement, le consommateur peut consommer plusieurs données avant d'être bloqué parce que le tampon est vide.
Comme son nom l'indique, un canal FIFO (First In / First Out) est un canal de communication où les données sont lues par le (ou les) consommateur(s), dans le même ordre que celui où elles ont été écrites par le (ou les) producteur(s). Une FIFO possédant une capacité de stockage de N données peut donc être dans (N + 1) états, puisqu'elle peut contenir 0, 1, ... N données.
Dans une FIFO logicielle de capacité N, les données sont stockées dans un tableau circulaire BUF[N] en mémoire, et l'état de la FIFO est défini par trois variables, qui sont également stockées en mémoire :
- PTW (pointeur en écriture) : numéro de la première case libre à écrire (modulo N)
- PTR (pointeur en lecture) : numéro de la première case pleine à lire (modulo N)
- STS (contenu de la FIFO) : nombre total de données présentes dans la FIFO (N + 1 valeurs possibles)
Le principe général est le suivant :
- La tâche productrice qui souhaite écrire une donnée consulte la variable STS dans une boucle d'attente active, jusqu'à ce que STS soit strictement inférieur à N. Quand c'est le cas, elle écrit la donnée dans la case BUFFER[PTW], puis incrémente PTW (modulo N), et incrémente STS.
- La tâche consommatrice qui souhaite lire une donnée consulte la variable STS dans une boucle d'attente active, jusqu'à ce que STS soit strictement supérieur à 0. Quand c'est le cas, elle lit la donnée dans la case BUFFER[PTR], puis incrémente PTR (modulo N), et décrémente STS.
- La FIFO étant gérée comme un tampon circulaire, les deux pointeurs PTR et PTW doivent être incrémentés modulo N.
Remarque sur les accès concurrents aux variables partagées :
- La variable d'état STS et les deux pointeurs PTW et PTR garantissent qu'une même case BUFFER[i] n'est jamais accédée simultanément en lecture et en écriture. Il n'y a donc pas de risque d'accès concurrents pour les éléments BUFFER[i].
- Dans le cas où il n'y a qu'une seule tâche productrice et une seule tâche consommatrice, la variable PTW n'est modifiée que par l'unique tâche productrice, et la variable PTR n'est modifiée que par l'unique tâche consommatrice. PTR et PTW ne sont donc pas des variable partagées. La seule variable partagée suceptible d'être modifiée simultanément par les deux tâches est la variable STS.
- Dans le cas où il y a plusieurs tâches productrices et plusieurs tâches consommatrices, les trois variables PTW, PTR, STS peuvent être accédées concurremment par plusieurs tâches pour être incrémentées ou décrémentées.
Les accès concurrents aux variables STS, PTW et PTR peuvent entraîner des incohérences : par exemple, si un producteur et un consommateur lisent simultanément la variable STS pour la modifier, la valeur finale sera fausse : suivant l'ordre dans lequel sont exécutées les écritures, on obtiendra (N+1) ou (N-1), alors que la valeur N devrait être inchangée.
Pour résoudre ce problème d'accès concurrent, une technique consiste à garantir un accès exclusif au canal de communication par un verrou binaire.
Finalement, toute tâche (productrice ou consommatrice) qui souhaite accéder à la FIFO doit respecter le protocole suivant :
- prendre le verrou (ceci peut entrainer une attente active).
- tester l'état de la variable STS pour déterminer si le transfert est possible (FIFO non pleine pour une écriture / FIFO non vide pour une lecture)
- si le transfert est impossible, relâcher le verrou et retourner en 1.
- si le transfert est possible, effectuer le transfert, incrémenter le pointeur concerné, modifier STS, puis relâcher le verrou.
Le fichier main_fifo.c contient une application producteur / consommateur utilisant un canal de communication FIFO. Dans l'application précédente, les périodes des accès (en lecture comme en écriture) étaient constantes et définies par les variables PRODUCER_DELAY et CONSUMER_DELAY. Dans cette application, on utilise la fonction rand() pour modéliser de façon plus réaliste un temps variable (et imprédictible) entre deux accès au canal de communication.
Le verrou _ioc_lock utilisé dans le TP8 était un verrou dans l'espace système, utilisé par le système d'exploitation pour séquentialiser les accès au contrôleur de disque. Le verrou utilisé ici pour protéger l'accès exclusif au canal de communication est un verrou dans l'espace utilisateur, qui est directement géré par le code applicatif grâce aux deux fonctions lock_acquire() pour la prise de verrou, et lock_release() pour la libération du verrou. Elles sont définies dans le fichier main_fifo.c. Pour garantir une allocation équitable entre les différentes tâches, ce verrou implémente une technique de ticket, ce qui nécessite de définir une structure contenant deux variables entières : la variable free représente le numéro du prochain ticket libre. La variable current contient le numéro du ticket du propriétaire courant.
Question F1 : Le canal de communication est défini comme une structure C du programme applicatif. Pourquoi cette structure est-elle déclarée comme une variable globale ? Quels sont les différents champs de la structure ?
Question F2 : Pourquoi est-il préférable d'utiliser un verrou à ticket plutôt qu'un verrou simple comme dans le TP8 ?
Question F3 : Quelles sont les arguments des deux fonctions lock_acquire() et lock_release() ?
Question F4 : Décrivez précisément ce que fait la fonction lock_acquire() pour prendre le verrou. Pourquoi la fonction atomic_increment(), appelée par la fonction lock_acquire(), est-elle écrite en assembleur ? Expliquez très précisément ce que fait cette fonction atomic_increment().
Question F5 : Que fait la fonction lock_release() pour libérer le verrou ? Expliquez pourquoi cette fonction n'a pas besoin d'être écrite en assembleur ?
Question F6 : pourquoi une tâche qui ne peut effectuer son transfert à cause de l'état de la FIFO (FIFO pleine pour un producteur / FIFO vide pour un consommateur) doit-elle impérativement relâcher le verrou avant de re-essayer ? Que se passe-t-il si elle ne le relâche pas ?
Question F7 : Complétez le code des fonctions fifo_read() et fifo_write() qui doivent réaliser le protocole de communication décrit ci-dessus.
Compilez l'application logicielle main_fifo.c en modifiant le Makefile dans le répertoire soft et lancez l'exécution pour différentes valeurs du paramètre DEPTH définissant le nombre de cases de la FIFO, sans oublier d'activer le SNOOP :
$ ./simul.x -NPROCS 2 -SNOOP 1
Question F8 : Relevez les dates de terminaison des deux tâches, et reportez ces valeurs dans le tableau ci-dessous. Quelles conclusions peut-on en tirer ?
| DEPTH | 1 | 2 | 4 | 8 |
| Producer | ||||
| Consumer |
Dans les applications parallèles, il est intéressant d'évaluer séparément le temps de calcul et le temps de communication.
- Le temps de calcul est une caractéristique intrinsèque de chaque tâche, et correspond au nombre de cycles utilisés par la tâche pour effectuer les calculs dont elle est responsable.
- Le temps de communication est le temps utilisé pour réaliser les opérations de lectures ou d'écritures dans les canaux de communication (y compris les temps passés dans les boucles d'attente liées à la synchronisation).
Question F9 : Evaluez le coût moyen (en nombre de cycles) d'une opération de communication entre deux tâches. Il faut pour cela réduire au strict minimum les temps de calcul autres que les appels aux fonctions fifo_read() et fifo_write() dans les tâches producer() et consumer():
- supprimer les temporisations,
- supprimer l'affichage à l'intérieur de la boucle
- augmenter le nombre d'itérations (1000 itérations)
L'augmentation du nombre d'itérations permet de négliger le coût de la phase de boot, et le coüt des deux affichages en début et fin des deux fonctions producer() et consumer().
G. Application logicielle multi-tâches
Le canal de communication FIFO protégé par verrou supporte plusieurs producteurs et plusieurs consommateurs.
Modifiez le fichier main_fifo.c pour écrire une troisième application logicielle dans un fichier main_router.c, comportant 6 tâches et deux canaux de communication A et B, suivant le schéma ci-dessous : une tâche productrice, quatre tâches de traitement, et une tâche consommatrice.
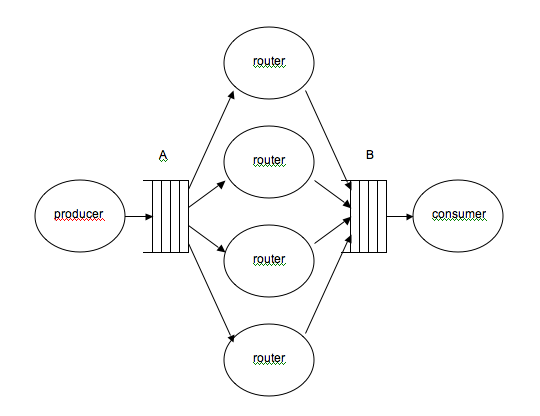
Cette structure correspond par exemple à une application de routage réseau, où la tâche productrice écrit dans le canal A des descripteurs de paquets réseau WIFI reçus sur un récepteur RF. Les tâches de traitement sont chargées d'analyser l'en-tête de chaque paquet reçu pour déterminer vers quelle destination le paquet devra être routé, et d'enrichir le contenu du paquet pour marquer cette destination, avant de copier le descripteur de paquet dans le canal B. Finalement, la tâche consommatrice relit les descripteurs de paquets et les envoie sur le canal de sortie correspondant à la destination choisie...
Notre but ici est simplement de vérifier le bon fonctionnement des canaux de communication. Les tâches se contentent donc d'échanger des jetons numérotés plutôt que des descripteurs de paquets, ce qui permet de vérifier qu'aucun jeton n'est perdu et qu'aucun jeton n'est transmis deux fois..
- la tâche producer envoie des jetons numérotés de 1 à 50 dans le canal A, en affichant sur son terminal un message à chaque jeton transmis, et s'arrête après avoir envoyé 50 jetons.
- La tâche router est répliquée 4 fois. Elle exécute une boucle infinie dans laquelle elle consomme un jeton dans le canal A, affiche le numéro du jeton sur son terminal, et le transmet vers le canal B après un temps aléatoire défini par la fonction rand().
- La tâche consumer possède un tableau local array[50], et exécute une boucle de 50 itérations dans laquelle elle lit un jeton sur le canal B, et stocke le jeton lu dans la case du tableau correspondant au numéro du jeton, en vérifiant que ce jeton n'a pas déjà été reçu. Après 50 itérations, elle sort de la boucle, et vérifie que tous les jetons ont bien été reçus (c'est à dire array[i] == i pour tout i) et s'arrête avec un message de diagnostic.
Question G1 : Que faut-il modifier dans le fichier reset.s pour lancer six tâches sur six processeurs différents ?
Question G2 : Le but du verrou est d'interdire les accès concurrents à une même resource (matérielle ou logicielle). Pourquoi est-il préférable de définir un verrou indépendant pour chaque canal de communication, plutôt que de définir un unique verrou pour tous les canaux ?
H. Compte-rendu
Les réponses aux questions ci-dessus doivent être rédigées sous éditeur de texte et ce compte-rendu doit être rendu au début de la séance de TP suivante. De même, le simulateur, fera l'objet d'un contrôle (par binôme) au début de la séance de TP de la semaine suivante.
Attachments (3)
- tp9_multi_taches.png (32.4 KB ) - added by 15 years ago.
- tp9_topcell.png (31.3 KB ) - added by 15 years ago.
- multi_tp9.tgz (3.9 KB ) - added by 16 months ago.
{kind=link}
{kind=link}
Download all attachments as: .zip