
TP3 : Déploiement de l'application MJPEG sur une architecture multiprocesseur
TP Précédent : TP2_Monopro
0. Objectif
Comme pour les précédents TP, vous aurez à fournir un certain nombre de sources et un rapport. Il vous est conseillé de parcourir la documentation dans le trac, en partant de dsx:wiki:WikiStart.
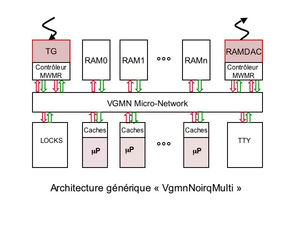
La première partie de ce TP vise la description d'une architecture matérielle multiprocesseurs générique, appelée VgmnNoirqMulti. Cette architecture est générique dans le sens où on peut faire varier par un simple paramètre le nombre de processeurs et le nombre de bancs mémoire, ainsi que les caractéristiques des caches rattachés aux processeurs.
La seconde partie de ce TP vise à déployer l'application MJPEG sur cette plateforme générique en faisant varier les paramètres dont on dispose. Cette exploration architecturale est le but réel de l'outil DSX.
1. Description de l'architecture générique VgmnNoirqMulti
L'architecture VgmnNoirqMono utilisée dans le TP2 était une architecture mono-processeur non-paramètrable.
On se propose de décrire maintenant avec DSX une architecture multiprocesseur générique (illustrée ci-contre), dont les paramètres sont :
- Le nombre de processeurs :
proc_count - Le nombre de bancs mémoire :
ram_count - Le nombre de lignes des caches :
icache_linesetdcache_lines - Le nombre de mots par ligne des caches :
icache_wordsetdcache_words

Cette architecture comportera également un contrôleur de terminaux (MultiTty).
Vous pourrez vous inspirer de l'architecture VgmnNoirqMono définie dans le TP2, en n'hésitant pas à utiliser les constructions du langage Python permettant d'exprimer la généricité (tableaux, boucles, etc.) Cette architecture générique VgmnNoirqMulti sera décrite dans un fichier DSX séparé, pour faciliter sa réutilisation.
Vous pouvez ajouter des paramètres à la fonction définissant l'architecture, auxquels des valeurs par défaut peuvent être spécifiées. Par exemple :
def VgmnNoirqMulti( proc_count, ram_count, icache_lines = 16, icache_words = 8,
dcache_lines = 16, dcache_words = 8 )
Vous validerez cette architecture générique VgmnNoirqMulti, en déployant l'application MJPEG sur une instance particulière de cette architecture, équivalente à celle utilisée dans le TP2 : c'est à dire un seul processeur et deux bancs mémoire. Pour l'architecture matérielle, vous spécifierez des caches processeurs de 16 lignes de 8 mots, et pour la partie logicielle, vous utiliserez le système d'exploitation embarqué Mutek/S.
Vous instancierez l'architecture avec la ligne (les paramètres non spécifiés prennent leurs valeurs par défaut) :
archi = VgmnNoirqMulti( proc_count = 1, ram_count = 2 )
- Question 1 : Combien faut-il de cycles pour décompresser 25 images?
2. Exploration Architecturale
Dans cette seconde partie, on va déployer l'application MJPEG sur l'architecture MPSoC VgmnNoirqMulti. Vous ferez principalement varier le nombre de processeurs et la répartition des tâches logicielles sur les processeurs. Les deux tâches d'entrée/sortie tg et ramdac restent pour le moment implantées sur des coprocesseurs matériels spécialisés : il y a donc 5 tâches "logicielles" à déployer sur un nombre de processeurs qui reste à déterminer.
2.1 Profilage de l'application
Pour guider la répartition des tâches sur les processeurs, on commence par effectuer un profilage de l'application sur station de travail POSIX, en mesurant les temps passés dans les différentes tâches.
Ce profilage nous donne, comme charge relative entre les tâches, les valeurs suivantes :
| idct | 35% |
| vld | 25% |
| demux | 20% |
| iqzz | 16% |
| libu | 4% |
- Question 2 : Qu'en déduisez-vous sur les façons optimales de déployer MJPEG sur 2, 3, 4 et 5 processeurs ? Expliquez votre démarche.
2.2 Déploiement sur une architecture à 5 processeurs
Déployez l'architecture MJPEG sur une architecture VgmnNoirqMultiPro comportant cinq processeurs, (c'est à dire une tâche par processeur) et lancez la simulation.
- Question 3 : Combien faut-il de cycles pour décompresser 25 images?
On cherche maintenant à estimer le taux d'utilisation de chacun des 5 processeurs.
- Question 4 : Quel est selon vous le processeur le plus chargé ? Expliquez une manière de le vérifier expérimentalement et faites cette vérification.
2.3 Déploiement sur des architectures à 4, 3 et 2 processeurs
Déployez l'application MJPEG sur des architectures matérielles comportant 4, puis 3, puis 2 processeurs, en utilisant les informations données sur les charges de chacune des tâches. Pour cela, placez intelligemment les tâches de façon à obtenir les temps de décompression les plus courts possibles.
- Question 5 : Quel est le nombre de cycles minimal pour décompresser 25 images avec 4 processeurs ?
- Question 6 : Quel est le nombre de cycles minimal pour décompresser 25 images avec 3 processeurs ?
- Question 7 : Quel est le nombre de cycles minimal pour décompresser 25 images avec 2 processeurs ?
2.4 Influence de la taille des caches
On souhaite maintenant évaluer l'influence de la taille des caches processeurs sur le temps de décompression. Utilisez la ligne de commande de votre description pour lui passer systématiquement la taille des caches :
# debut du fichier de description # important: importer dsx en premier from dsx import * import sys dcache_lines = int(sys.argv[1]) icache_lines = int(sys.argv[2])
Utilisez ensuite les deux variables dcache_lines et icache_lines dans votre description.
On se place dans l'hypothèse d'une architecture à 2 processseurs, en conservant le placement des tâches optimal défini à la question précédente. On utilisera des lignes de cache de 8 mots, et on se contentera de faire varier le nombre de lignes.
- Mesurez le temps de calcul pour décompresser 12 images, en utilisant deux "gros" caches de 1024 lignes, pour les instructions comme pour les données.
- Refaites cette mesure en diminuant progressivement le nombre de lignes du cache de données (256, puis 64, 16, 4 et enfin, 1), en conservant une capacité de 1024 lignes pour le cache d'instructions.
- Idem en diminuant progressivement le nombre de lignes du cache d'instructions (256, puis 64, 16, 4, et enfin 1), en conservant une capacité de 1024 lignes pour le cache de données.
- Question 8 : Regroupez ces résultats dans deux tableaux de synthèse.
- Question 9 : Que choisiriez-vous comme capacité pour les caches, sachant que la surface de la mémoire embarquée est un facteur important du coût de fabrication (vous comparerez en particulier la capacité des caches à la capacité des bancs mémoire
ram0etram1).
3. Compte-Rendu
Comme pour les TP précédents, vous rendrez une archive contenant les fichiers suivants :
$ tar tzf binome0_binome1.tar.gz tp3/ tp3/rapport.pdf tp3/mjpeg/ tp3/mjpeg/mjpeg tp3/mjpeg/vgmn_noirq_multi.py tp3/mjpeg/src/ tp3/mjpeg/src/iqzz/iqzz.c tp3/mjpeg/src/libu/libu.c
Le fichier mjpeg sera celui de la partie 2.4, avec la gestion de la ligne de commande. Les deux sources C sont ceux des deux derniers TP, éventuellement modifiés.
Envoyez cette archive au plus tard la veille de la séance du TP 4, à [MailAsim:Quentin.Meunier Quentin Meunier]. Tout retard sera sanctionné.
Suite
TP Suivant : TP4_Multipipe
Attachments (1)
- VgmnNoirqMulti.png (88.2 KB ) - added by 15 years ago.
{kind=link}
Download all attachments as: .zip