
TP4 : Exécution sur architecture multi-cluster
TP Précédent: TP3_Multipro
0. Objectif
On cherche dans ce quatrième TP à augmenter encore le débit de la chaîne de décompression, pour permettre - par exemple - de traiter des images de plus grandes dimensions, tout en respectant la fréquence video.
Cette augmentation de débit peut être obtenue en augmentant la fréquence d'horloge, mais cette approche a évidemment des limites. On essayera donc plutôt d'augmenter le parallélisme de traitement du flux MJPEG.
Pour augmenter le parallélisme, il ne suffit pas d'augmenter uniquement le nombre de processeurs dans l'architecture matérielle, mais également augmenter le nombre de tâches de l'application logicielle (afin d'utiliser ces nouveaux processeurs) : cela impose de modifier la structure du TCG.
- La première partie du TP vise la définition d'un graphe de tâches multi-pipeline.
- La seconde partie du TP porte sur la définition d'une architecture matérielle multi-clusters.
- La troisième partie du TP analyse l'impact du placement des canaux de communication sur les bancs mémoire dans les architectures de type NUMA (Non Uniform Memory Access).
Commencez par créer un répertoire de travail tp4, et recopiez dans ce répertoire le contenu du répertoire tp3.
1. Parallélisation du TCG
Le TCG défini dans le TP1 et re-utilisé dans les TP2 et TP3 comportait 7 tâches. Il exploitait un parallélisme de type macro-pipeline : différentes tâches traitent différents blocs de la même image. Toutes ces tâches s'exécutent en parallèle, mais travaillent sur des blocs différents de l'image. Il est difficile d'augmenter le nombre d'étages de ce macro-pipeline, car les tâches les plus coûteuses en temps de calcul (VLD, IQZZ et IDCT) ne se découpent pas facilement en sous-tâches.

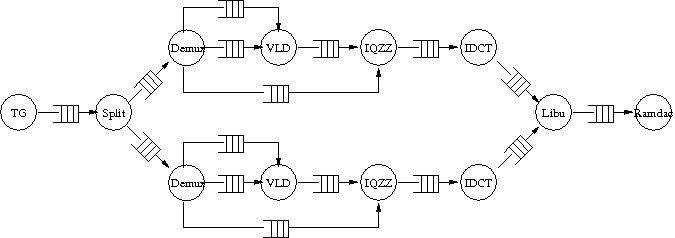
On va donc exploiter un autre type de parallélisme en utilisant deux pipelines de décompression (tel qu'illustré sur la figure ci-contre). Chaque pipeline traite une image complète. Pour ce faire, on introduit une tâche chargée de distribuer aternativement aux deux pipe-line le flux MJPEG. Cette nouvelle tâche, nommée 'split', se situera entre les tâches 'tg' et 'demux'. La tâche 'libu' doit être modifiée pour récupérer alternativement les images décompressées provenant des deux pipelines, avant de les envoyer vers la tâche 'ramdac'.
Modifiez la structure du TCG dans la description DSX de l'application pour introduire un nouveau modèle de tâche pour la tâche split, puis modifiez le modèle de la tâche libu. Il faut ensuite modifier la topologie du TCG en définissant explicitement toutes les intances de tâches et tous les canaux de communication nécessaires.
Le code de la tâche split doit analyser octet par octet le flux MJPEG, précisement en détectant le marqueur de début d'image (SOI = 0xffd8), de façon à l'aiguiller vers le bon canal de sortie.
Le pseudo-code correspondant à l'algorithme de split est :
canal de sortie = le premier
toujours :
b = lire un octet
si b == 0xff
m = lire un octet
si m == 0xd8
remplir la sortie courante de 0xff
envoyer le bloc
changer de canal de sortie
écrire b dans la sortie
écrire m dans la sortie
retourner au début de la boucle
écrire b dans la sortie
Conseils :
- pensez à utiliser l'API des
'block_io', pour laquelle vous pourrez trouver un exemple d'utilisation dans la tâchedemux(les fonctions proposées par l'API'block_io'sont visibles dans'common/block_io.h'). - pour que les deux pipelines de décompression puissent vraiment travailler de manière parallèle, il faut choisir une profondeur de canal de communication adéquate entre
splitet les deux instances dedemux. Idem pour les canaux entre les deux instances deidctetlibu.
Question 1 : En supposant que le temps d'écriture dans les canaux MWMR est négligeable devant le temps de traitement d'un pipeline, quelle taille faut-il choisir pour les canaux entre split et demux pour obtenir un parallélisme performant ? Entre idct et libu ? Justifiez votre réponse.
Pour valider fonctionnellement cette nouvelle description de l'application logicielle, commencez par la déployer sur une station de travail POSIX. Vous devez normalement voir les mêmes images qu'avant, dans le même ordre.
2. Architecture matérielle multi-processeur clusterisée
Pour supporter la charge induite par ces nouvelles tâches, il faut augmenter le nombre d'unités de traitement (processeurs ou coprocesseurs). Afin d'éviter que l'accès à la mémoire ne devienne un goulot d'étranglement, il est également souhaitable d'augmenter le nombre de bancs mémoire physique, de façon à répartir les données. Et lorsque le nombre d'entités communicantes (initiateurs ou cibles) augmente, il est utile de structurer l'architecture en sous-systèmes distincts.
Cette structuration a des justifications fonctionnelles :
- On cherche à regrouper dans un même sous-sytème les différents composants matériels qui réalisent une même partie de l'application, et qui communiquent fortement entre eux.
- Elle facilite également la réalisation matérielle : chaque sous-système pourra être implanté physiquement dans un même domaine synchrone, et utiliser sa propre horloge, conformément au principe GALS (Globally Asynchronous, Locally Synchronous).

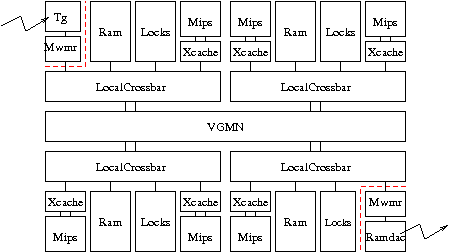
Chaque sous-système constitue un cluster (ou encore grappe), et contient des processeurs, de la mémoire, et dispose de son propre mécanisme d'interconnexion local.
Les différents clusters sont interconnectés entre eux par un micro-réseau à interface VCI, qui pourra être modélisé par un composant Vgmn.
On utilisera comme mécanisme d'interconnexion interne à chaque cluster le composant LocalCrossbar (voir dsx:wiki:SoclibComponents). Ce composant matériel est un petit crossbar (tous les composants initiateur sont physiquement reliés à tous les composants cible), qui possède un nombre variable de ports initiateur et cible permettant de connecter les composants matériels appartenant au cluster. Il possède également deux ports initiateur (initiator_to_up) et cible (target_to_up) permettant l'accès au micro-réseau.
Cette structuration aboutit donc à l'utilisation d'un mécanisme d'interconnexion à deux niveaux (interconnect global : Vgmn, et interconnect local : LocalCrossbar), bien que tous les composants matériels (initiateurs et cibles) continuent à partager le même espace d'adressage.
Pour faciliter l'exploration architecturale, on souhaite définir une architecture générique dont les paramètres sont:
- la latence minimale du Vgmn
- le nombre de clusters et, pour chaque cluster,
- le nombre de bancs mémoire
- le nombre de processeurs
Utilisez la définition de l'architecture ClusteredNoirqMulti que vous copierez dans le fichier 'clustered_noirq_multi.py'.
3. Déploiement et exploration architecturale
En reprenant le fichier de description DSX mjpeg :
- Remplacez l'instanciation de VgmnNoirqMulti par
archi = ClusteredNoirqMulti( cpus = [1, 2, 2, 1],
rams = [1, 1, 1, 1],
min_latency = 10 )
- Ajoutez la création des coprocesseurs
tgetramdacsur le premier et le dernier cluster respectivement, en suivant les indications présentes dans le fichier'clustered_noirq_multi.py'.
La structure de l'application logicielle (TCG), et l'architecture matérielle étant définies, l'exploration architecturale consiste donc à analyser l'influence du placement des objets logiciels sur les composants matériels. On s'intéresse tout particulièrement au placement des canaux de communication sur les bancs mémoire physiques.
Dans ce type d'architecture multi-clusters, les temps d'accès à la mémoire sont très différents, suivant qu'un processeur adresse la mémoire locale à son propre sous-système, la mémoire locale à un autre sous-système. On parle ainsi d'architecture NUMA (Non Uniform Memory Access).
Refaites le placement des tâches logicielles et des canaux de communication de manière intelligente. Pour les canaux, essayez ensuite de faire varier le placement de l'état par rapport au placement du tampon mémoire, de placer le canal plutôt du côté de la consommation, ou de la production, etc. Faites également varier les profondeurs de canaux entre split et les demux, et entre les idct et libu.
Pour effectuer cette exploration, sachez que les rams sont identifiées par un nom de la forme '[uc]ram<no cluster>_<no>', tandis que les processeurs sont identifiés par 'cpu<no cluster>_<no>'.
- Question 2 : Combien faut-il de cycles pour décompresser 25 images suivant les différents déploiement que vous aurez essayés ?
- Question 3 : Essayez d'en extraire un critère de performance en fonction des placements.
Pour cette question, si vous trouvez la simulation trop longue pour 25 images, vous pouvez arrêter avant. Néanmoins, ne vous basez pas sur la simulation pour une image, car le pipeline de traitement est vide au départ. Essayez de prendre au moins 7 images, et d'ignorer le temps de remplissage (2 premières images).
4. Compte-Rendu
Comme pour les TP précédents, vous rendrez une archive contenant :
$ tar tzf binome0_binome1.tar.gz tp4/ tp4/rapport.pdf tp4/mjpeg/ tp4/mjpeg/mjpeg tp4/mjpeg/clustered_noirq_multi.py tp4/mjpeg/src/ tp4/mjpeg/src/libu/libu.c tp4/mjpeg/src/libu/libu.task tp4/mjpeg/src/split/split.c tp4/mjpeg/src/split/split.task
Envoyez cette archive au plus tard la veille de la séance du TP 5, à [MailAsim:Quentin.Meunier Quentin Meunier]. Tout retard sera sanctionné.
Suite
TP Suivant: TP5_Coproc
Attachments (2)
- mjpeg_multi.png (5.7 KB ) - added by 15 years ago.
- clustered_noirq_multi.png (4.8 KB ) - added by 15 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip